Abstract: Generative AI is flooding the internet with hyperreal images. Can surrealism save us from hyperrealism? Surrealism uncovers the reality that nobody wants to face: the surreal, i.e., the real that is more real than the real. This lecture introduces Pixelated Dreams, a surrealist game that uncovers the reality of generative AI. Instead of turning everyone into an artist, these systems turn artists into half-machine, half-people, living dead, generating art on demand at no compensation or credit. Pixelate Dreams develops critical consciousness of these systems and inspires designers to create their own artificial intelligence.
This lecture was pre-recorded in the Fall 2024 Research and Practice MXD MFA course at the University of Florida.
Video
Audio
Full transcript
This is going to be a timely reflection on how we can meaningfully respond to the challenge posed by generative AI from a critical artistic and design perspective. First of all, let me share what the challenge posed by it is.
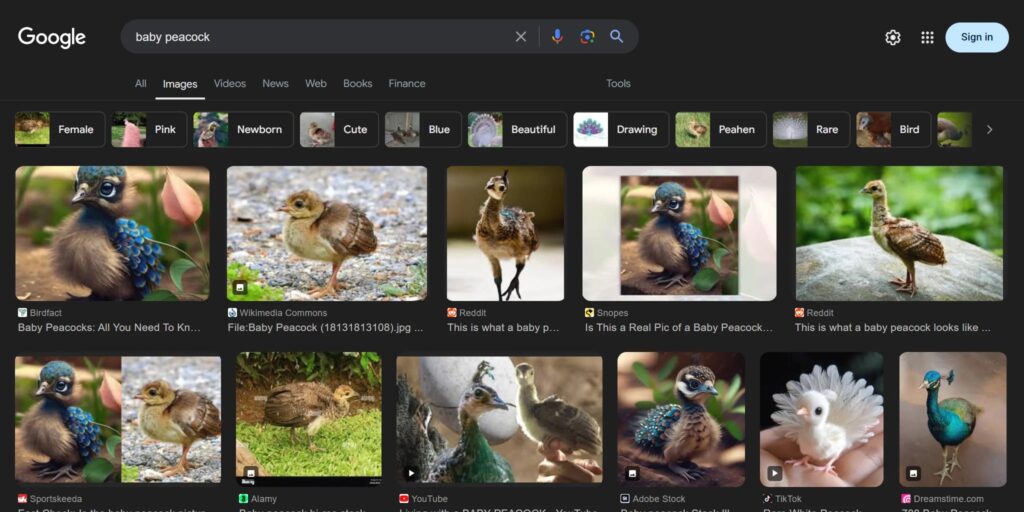
So many people are using generative AI and publishing their social media posts, but there are also robots producing fake websites with fake images, and very few people are actually overseeing this activity to the point of flooding Google search results. If you search, for example, “baby peacock” on Google Image Search, you may not find an image of a real peacock. By now, if we look at them, we can more or less tell the difference, but wait a few months, and we will not be able to tell the difference between an image of an actual photograph of a baby peacock and a generative AI image of that peacock. Eventually, something else will come out that is not at all a peacock, and we may get used to the image of a baby peacock being actually cuter than it is in real life, and at some point, we might really take that image as the reality of “baby peacock”.
Well, that is something that is not new at all; it’s not an innovation. It has been denounced by Jean Baudrillard, a French philosopher who analyzed in the 70s and 80s the cognitive aspects of capitalism and this social production of reality that we are in. This regime of production of reality is where the referents or the objects that these images are referring to are no longer to be found, meaning that the signs become simulacra or a hyperreality where the imaginary becomes indistinguishable from the real.
I have to emphasize this because not many people nowadays, with such acceptance of postmodernism, hold on to this idea that, well, the imaginary may be even more real than the real. No, no, no. Unfortunately, the imaginary most of the time is less real than the real because that’s exactly what the function of imagination is: to go into a virtual reality, something that’s not yet real. Don’t get me wrong—virtual reality is not real yet, but maybe in the future, it will be. So, there is a point in imagining. I’m not saying that’s a bad thing; I’m just saying that if we cannot distinguish between those, we are in a very dangerous regime, and that’s exactly what Jean Baudrillard’s message was. It has been reflected on critically by many people since its publication. However, there are very few artistic and design responses to that, which try really to recover back this thing.
I have to go back to history and recover a bit of a few things because a lot of people are forgetting that surrealism was already anticipating what artificial intelligence was capable of more than 100 years ago. Surrealism did not just question the quality of the representation, whether the image was close to reality or not, to what extent it was distant, but most importantly, surrealism was questioning who got access or privilege to represent reality, to tell what was going on in the world.
For example, they engaged deeply with the World War I aftermath, this moment when people were figuring out what they had done, the amount of damage—not just physical and environmental damage but also psychological damage—and the role of media and propaganda in keeping people away from understanding what was going on in that reality. Surrealists devised many different artworks and approaches to address those contradictions brought forward by this control over information and understanding, and the information about ourselves most importantly. One of them, which became very popular even to these days, is the surrealist games, and they made through these games the unconscious more conscious. People would play these games to access the unconscious and express something that was being covered, that was being blocked or concealed in that psychological dimension.
These games were simple and ready to be played by anyone, even people who were not trained as artists, even people who didn’t have access to that specific kind of art. For example, a painter could actually write poetry by playing a surrealist game on poetry-making.

One of the most famous surrealist games is called automatic drawing and automatic writing. Here you see the muse of automatic writing, Hélène Smith. She was elected by the surrealists as such because she was wild in these experiments, for example, of writing by following the flow of consciousness non-stop without a filter, just letting the flow, right? And at some point, she was channeling Martians. She claimed to be telling stories from Mars, and then she even devised and developed this alphabet that came from Mars, which nobody could read, and only she could actually help interpret the messages coming from the aliens. And that’s why she was elected as the muse of automatic writing.
Think about it—how similar this is to current generative AI, right? We just need to draw simple analogies. What surrealists called unconsciousness roughly corresponds to today’s artificial intelligence latent space. What are those? Here, I’m going to borrow a few visualizations made by Ivan Echeverría, and he was trying to explain how those latent spaces and interpolation work. He was using this simple example of Lego figures’ heads as an object that has multiple variations so that people could understand what a latent space is. But this is definitely a simplification because latent spaces are so much bigger than what we can convey through a 2D image, right?
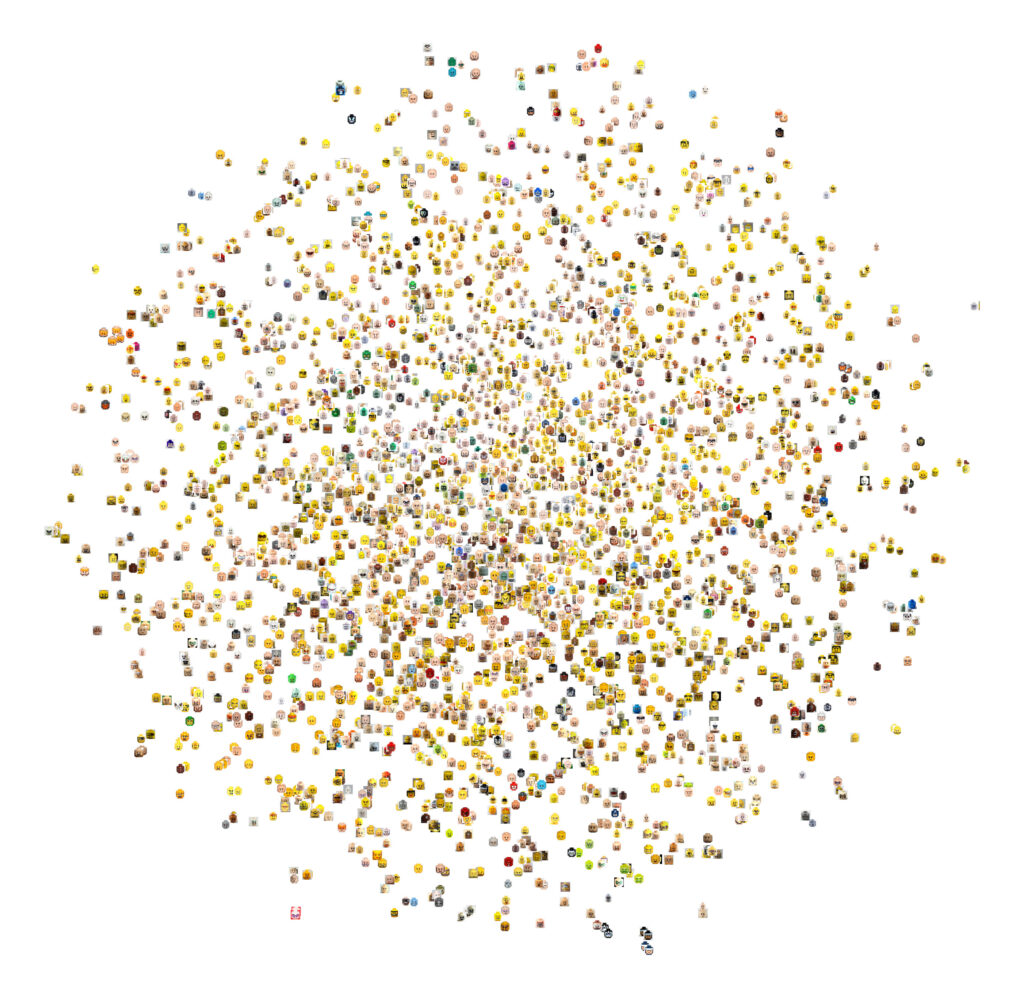
Most importantly, the function of it is to help cluster data by automatically recognizing patterns. So, it’s latent because that space can be overlapped and crisscrossed. So, you can see in this space how one thing relates to another. That’s why it’s called latent. Here you see three clusters that Echeverría picked as examples of what kind of advantage you get if you put this information in the same kind of space. You can start to see, for example, through automated recognition patterns that clusters emerge by some common visual features of these images. Well, it doesn’t need to be necessarily images, right? Latent spaces can relate textual data too. We’re just using images here because it’s so much quicker to understand what a pattern is.
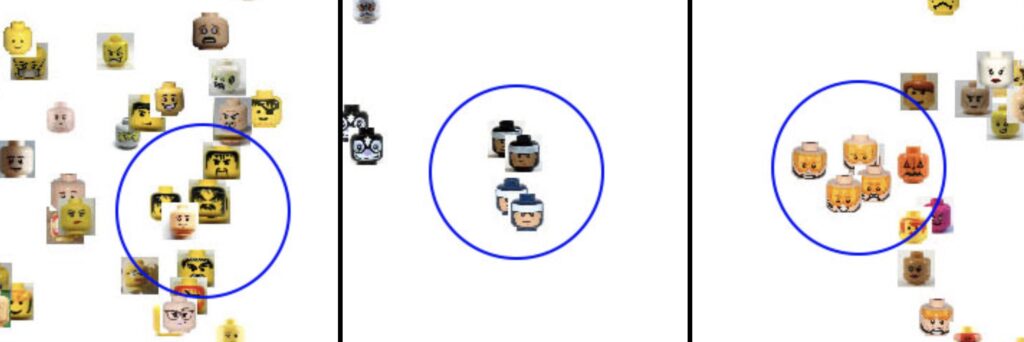
If you look at the images in the cluster on the left side, you will see that they share some kind of bandit appearance. They have a lot of unshaved hair; some of them have an angry expression on their face. So, these are the bandits’ cluster. And who calls that bandit? Who identifies this and gives it some meaning is the people behind it. The machine is just saying there’s some kind of visual resemblance. However, that visual resemblance is also used by humans to attach meaning to other people. For example, they might carry on some kind of visual patterns they have found out to new interactions, new people, and they might judge people by their faces, which is currently considered to be unethical. But in the past, and around the 19th century, there was even a science of physiognomy, phrenology, and other approaches to identify whether someone was a criminal just by looking at their face. And people were really brought to jail just because they looked like a criminal.
Of course, this science has been debunked because it didn’t yield good results. A lot of honest people were in prison, and that became something, unfortunately, still a practice that goes away and then comes back. For example, automated image recognition that also relies on this kind of latent spaces still performs this kind of prejudgment. And so these clusters that are formed by latent spaces, unfortunately, they are latent of human meaning, and the kind of prejudice that we develop in our world carries over to those spaces, especially if we don’t explicitly try to mend those biases.
One important thing to understand is that these latent spaces, they relate information in a way that can be speculated if there’s no direct connection. For example, you see here on the left side an image of two Lego faces. They are unrelated yet. However, they carry some basic, fundamental, synthetic relationships. They seem to be coming, for example, from the same kind of person, and it’s just variating the expression.

These blue dots that separate those two images, represent a possibility for the machine to generate new images that are gradually showing the transformation from one facial expression to another. That’s called interpolation. And that’s one of the most important aspects of generative AI, particularly for images, that it can interpolate data and generate new data if the data points are related by some kind of parameter.
Here, it’s not explicit what the parameter is, but as you can see, those two images, they are about the same distance from each other. On the left side, on top, you see three points on the Y scale and minus two on the X scale. That could be, for example, that this person is relaxed and happy. And on the rightmost side of the image, you see a face that is minus two on the Y scale and three on the X scale, which might mean someone who is relaxed but unhappy. Well, I don’t know exactly what those parameters mean, but what I mean is that if you have latent space, you can interpolate and generate new data that is already connected by filling in the gaps and borrowing some visual elements from those two images.
However, sometimes—actually, most of the time—when you ask for interpolations, generative AI will hallucinate, meaning that it will distort the data and generate images that are considered bad, wrong, mistaken, weird, uncanny, not recognizable. I’m just making a simple example here. I just got the first image and the last two images that you saw on the previous slide, and I asked them to be blended by MidJourney, one of the most important generative AIs of current times.
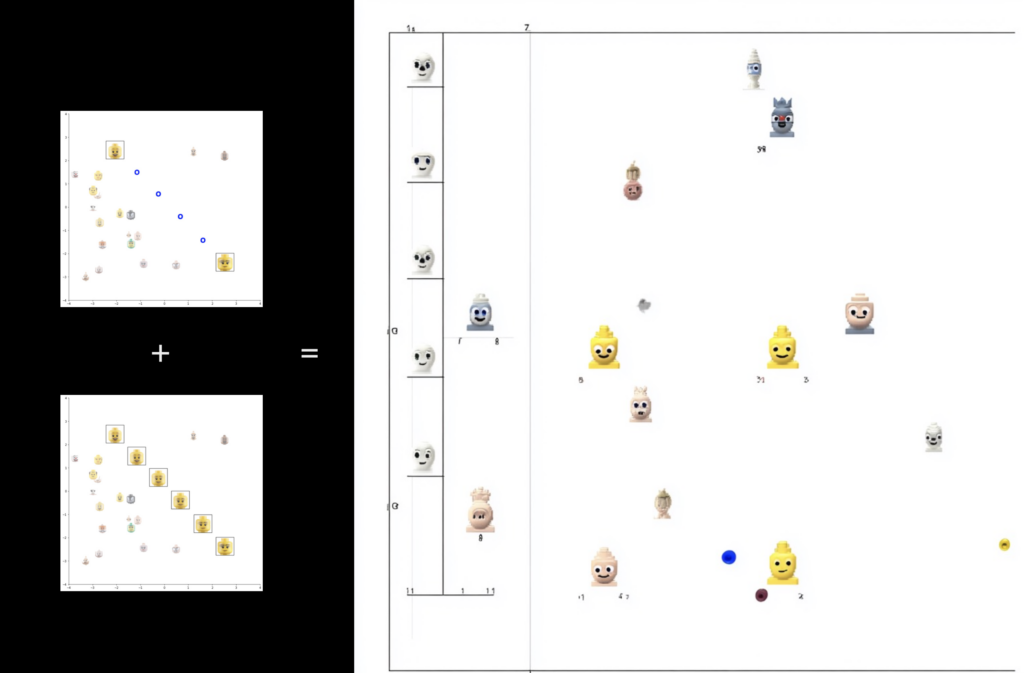
MidJourney generated this weird combination that definitely has no explanatory meaning to understand more how latent spaces work. However, there are some elements in this image, like some new faces that are very uncanny. Look at the ghost on the left side. There’s definitely some hallucination going on here, because if I go back to the past image, you cannot see anything like a ghost, right? There’s nothing like a ghost here. And we didn’t ask MidJourney to devise anything like a ghost.
But it generated a ghost, because it is trying to connect the different images out there, the different parts of the images, and trying to find what is common amongst them and speculate something that will be in between one image and the other image. And this is done by drawing on some vast amounts of interrelated data. MidJourney is not just drawing from those two images and blending them pixel by pixel. MidJourney is trying to interpret somehow and relate those images that I fed to the system with these thousands and millions of images that they have in their trained data. That’s how it becomes a bit uncanny. Otherwise, if I would just mix pixel by pixel, we would have more like an overlap image and not really an interpolated image.

Looking back to the surrealist movement, well, hallucinations, they are strangely familiar to surrealist imagery. Look at what happens here in this Salvador Dalí’s The Persistence of Memory, probably one of the most known surrealist paintings. You see clocks melting as if they were, I don’t know, some piece of meat or some piece of metal that has been heated. And he’s trying to create this uncanny situation on purpose so that people understand that time is that thing that flows and that we cannot really get a hold of.
We build clocks. These clocks are part of us as a kind of organic matter. And clocks are consumed by ants, as in the left bottom side of the image conveys. Well, there are many things that we can speculate about how we unconsciously perceive time here. I’m not going to go into that. I really want to address that what Salvador Dalí was doing here resembles visually, on a superficial level, to what generative AI does. Combining properties of one object with properties of another object, metadata, and then using that to generate a new kind of image that is uncanny precisely because clocks, they are typically built by sturdy material that does not melt like this.
Here’s how hallucinations become nasty. OpenAI, one of the most important companies pushing forth this technology, paid homage to and appropriated Salvador Dalí’s name, artwork, and creative process. Their flagship generative AI for image-making is called DALL·E, a combination between the famous robot figure WALL·E and Salvador Dalí’s surname. Unfortunately, OpenAI is not so aware, maybe, of the work of Salvador Dalí and what he stands for. Because if we read a paper written by computer scientists that work at OpenAI and have discussed and presented the algorithms behind DALL·E, you will see that they make some weird experiments using that same generative AI that looks not very, let’s say, respectful to the artist.
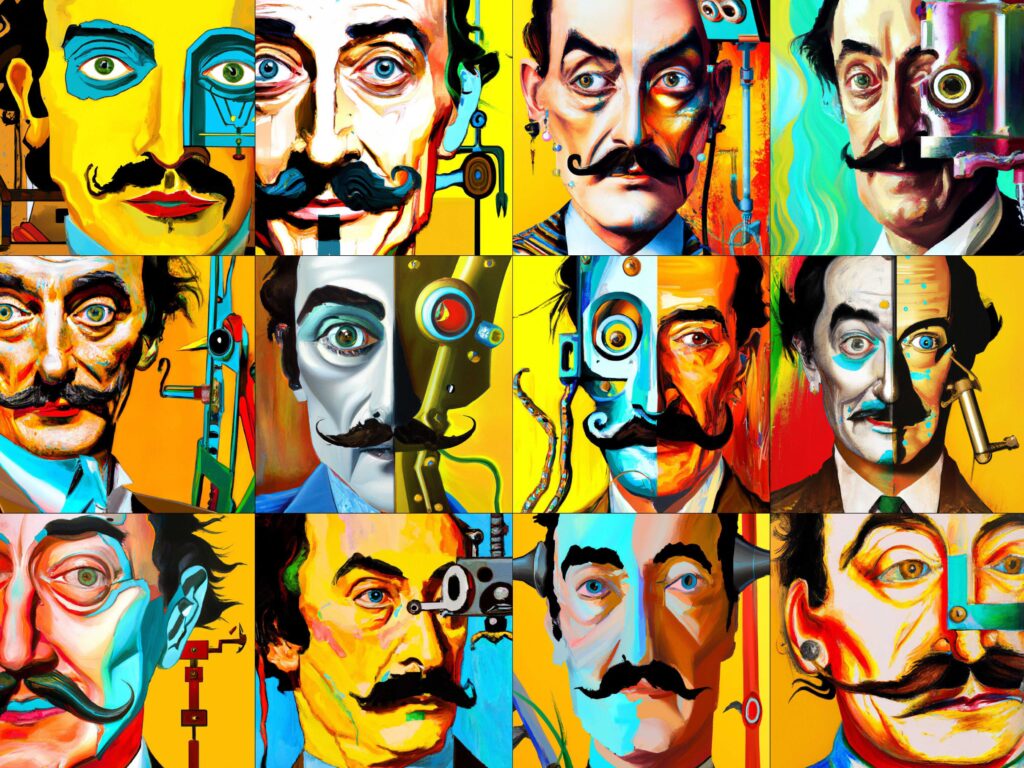
Here’s their prompt: “Vibrant portrait painting of Salvador Dalí with a robotic half-face.” The AI generated those images that are pretty horrible, and they don’t pay enough respect to the faces of the artist. Salvador Dalí really liked being in pictures, but he was always playing a mysterious face. If you look at the pictures here, most of them are not mysterious, and they look like either this person is mentally afflicted or is a dumb person. He’s not really preparing or posing for the picture, which is something that Salvador Dalí absolutely liked doing. I’m not saying that the algorithm should control this. I’m just saying that they are appropriating everything that artists have done just for the sake of their own popularity and not really paying respect to what he stands for.
The important question that many people are nowadays discussing is: did DALL·E enable everyone who has access to it—who can pay for it, and sometimes it’s not cheap—do they become an artist just because they can start generating any kind of image, even in Salvador Dalí’s style? Of course not. DALL·E turned artists into anonymous cyber zombie slaves. Imprisoned in this nightmarish black box of generative AI, they remain there as half-machine, half-people, living dead, generating art on demand at no compensation or even credit.
That’s only possible because DALL·E and other generative AI systems, they are scraping the web for millions of artists who have, in the past, shared their work for free on websites such as DeviantArt, where you can actually say, “Hey, look at the world, look, world, what I’ve got, and you can follow my work, and we can have a conversation. You may even hire me for my art.” Unfortunately, these artists could never imagine that one day a generative AI system would suck their artwork and generate something else without giving any credit, even incurring in some copyright infringements. Even if the artists have used a Creative Commons license that requires attribution to the person, this credit is not given currently by generative AI.
That’s so unlike Salvador Dalí himself, because he was really using his name as a brand, even offering it for product merchandise and television programs. He was a popular figure who profited from his name as a commercial artist. Dalí was definitely the most financially successful artist of the surrealist movement. Here, he’s posing in a picture at his house in Portlligat, Spain. I don’t think Salvador Dalí would like what’s going on with DALL·E—not giving credit to anyone, not letting artists become rich. He believed that artists deserve wealth. Why not? Why can’t artists become rich in capitalism if everyone else can? Why should artists remain poor? What’s the point of that?

Despite its name, DALL·E cannot be considered a surrealist machine. Instead, it’s better described as a hyper-realist machine. Now, I’m drawing from Jean Baudrillard’s concept of hyper-realism. Hyper-realism involves producing images with no traceable origin. We don’t know where they come from, and therefore, they are less real than the real. There’s no referent behind these images, no object or source we can pinpoint. The algorithms behind generative AI don’t reveal where these images originate because they draw from massive, trained datasets.
We know the data comes from millions of images, but we cannot trace any specific image used to generate a particular output. Currently, these systems don’t provide credits. I don’t know if they ever will, but as things stand, they are hyper-realistic machines generating untraceable images.
My research question, as a designer of these technologies, is: Can surrealism save us from hyper-realism? Let’s return to surrealism’s basic premise: it aims to uncover a reality that no one wants to face, the so-called surreal—the real that’s more real than the real. In surrealism, we’re not fleeing from reality. We’re not chasing something purely imaginary. Instead, we’re using imagination as a tool to reach a deeper reality. When we look at a surrealist image, we feel that something is at stake. If we keep engaging with it, we might better understand our reality.
René Magritte synthesized this idea brilliantly. He anticipated many of Baudrillard’s discussions in the 70s and 80s. Magritte’s work, like The Treachery of Images (1928), remains highly relevant. You’ve probably seen his famous painting that features a pipe with the caption, This is not a pipe. It’s often misinterpreted as simply the title of the work, but it’s not. The actual title is The Treachery of Images.

Magritte made the painting accessible by providing this title. Without it, understanding his intentions would be harder. He wanted to show that images can deceive us. They might make us feel like we’re looking at reality when, in fact, we’re only looking at representations. But what if images are all we have? What if everything we perceive as real is just an image?
Even the words “This is not a pipe” are not a pipe. A pipe itself isn’t just the physical object; it’s also a concept. Without the concept of a pipe, we wouldn’t know what to call that physical shape. This highlights how much we rely on signs and symbols to produce reality. And sometimes, we confront contradictions where we no longer know what is and what isn’t real. This doesn’t apply just to pipes; it applies to everything.
I tried to engage with Magritte’s work in my first experiments with MidJourney. I input the exact phrase: “Ceci n’est pas une pipe by René Magritte”. I was curious to see how the system would interpret it. Would it try to replicate the original artwork, or would it deviate? As you can see, the output structurally resembles Magritte’s painting because it features a pipe. But this pipe exists in a more symbolic space, with trees and clouds in the background—elements found in Magritte’s other works.

The AI also added an odd detail: grass growing out of the pipe’s extremity. It’s unsettling. What’s the connection between grass and pipes? But looking at Magritte’s body of work, such associations are common. If I didn’t disclose that this was generated by AI, many people might believe it’s an original Magritte. They’d describe it as nightmarish, outlandish, and mesmerizing, just like his other works.
But that was too easy. This experiment simply proved that Magritte’s themes remain relevant and that generative AI can produce hyper-real images that resemble famous artworks. But it doesn’t take us deeper. So, I decided to try ChatGPT+DALL·E 3, which allows for richer prompts and iterative refinement. Unlike MidJourney, which operates on trial and error, ChatGPT+DALL·E 3 enables a dialogical process. You can refine your prompts, tell the system what to adjust, and iteratively improve the output.
I asked ChatGPT+DALL·E for a critical self-portrait. I wanted DALL·E to reflect on itself—its nature, its impact, its contradictions. The initial images weren’t what I was looking for, so I kept pushing: “Is this really you? Are you hiding something? Show me your true self.” After several iterations, this is what I got.

The image is unsettling, which was my goal. I wanted it to provoke thoughts about the environmental and social impacts of generative AI. I reminded DALL·E of its reliance on appropriating artworks from marginalized artists—many of whom are non-white, seeking opportunities in an unequal world. Most generative AI tools primarily serve white users, yet much of their source material comes from underrepresented communities.
At one point, when seeing a black face emerging, I asked: “Why you depict yourself as non-white, if most of your programmers, trainers, and users are white?” This iterative process led to an image that felt uncanny and discomforting, exactly as I intended. It forces viewers to confront the hidden costs of generative AI, both social and environmental. And yes, there’s a contradiction in using DALL·E against itself—but that’s the point.
I brought this forward to discuss with my peers at the Design Research Society Conference in Boston last June. Together with Mariana Fonseca Braga and David Perez, we organized a conversation called Social Design at the Brink. During one moment in this conversation, we showed this picture and asked our peers to critically discuss what was being depicted. What was the contradiction behind this image? We didn’t provide any explanation or labels. The sticky notes you see here were added by participants, people who were “reading” this image and discussing it.
We wrote a paper reporting on this. Importantly, we drew from a method called the Cultural Circle, which was devised by Paulo Freire in the 1960s. He used the term generative image. Of course, Freire didn’t have artificial intelligence in mind when he used this term. What he meant was that if you showed an image and facilitated a dialogue around it, that image could generate themes for discussion. That’s why they were called generative images. However, not just any image would work. They had to be designed and created in a way that conveyed contradictions relevant to the lives of the people discussing them.
We conducted studies to identify the main contradictions being discussed by social designers at the time. This is why we introduced generative AI, particularly focusing on its social and environmental impact, as an example of a disruptive technology of our times that everyone wanted to discuss. This background research informed our activity, which generated, as expected, a robust debate.
Now, my take on this, and what the Surrealists also did: instead of denying instrumental rationality, as the Dadaists did, the Surrealists pitted rationality against itself. Let’s look at these examples. On the left, there’s a Dadaist collage by Hannah Höch, and on the right, a Surrealist collage by Max Ernst. At first glance, you’ll notice that the Dadaist collage has little regularity, while the Surrealist collage shows some kind of grid or order, even though both images are chaotic.

The Surrealists used emerging rationality against itself as a form of critique. The Dadaists, on the other hand, argued that rationality leads to irrationality and generates global conflict, particularly wars. Their work often depicted technology as oppressive, symbolically crushing people. Dadaism was an escape from the madness of being entirely driven by machines. It aimed to recover spontaneity lost in the industrial society—a society that created weapons of mass destruction, turning technology against humanity. In contrast, Max Ernst explored how rationality suppresses unconscious desires, which eventually resurface and demand fulfillment. Rationality, in his view, could both conceal desires and serve as a means to fulfill them if redirected properly.
Inspired by the Surrealists, I’ve been exploring how artificial intelligence—particularly generative AI—works and how we can use it against its inherent biases. I’ve experimented with this and found it a compelling approach. Playing surrealist games is an excellent way to achieve this. For many years, I’ve used surrealist games with my design students to foster creativity, particularly collective creativity. Students play Exquisite Corpse, the most famous Surrealist game, as well as lesser-known ones like Entopic Graphomania, which involves finding a text within a text, and Automatic Drawing, among others. The Book of Surrealist Games by Alastair Brotchie and Mel Gooding has been a key reference for me. It compiles many such games, but I also find inspiration online, which provides a valuable source of new ideas, moving beyond traditional brainstorming methods commonly used in design creativity.

Surrealist games and generative AI share common mechanisms. Both tap into the collective unconscious, explore a vast space of possibilities, and combine elements in unexpected ways, capitalizing on the chance of something surprising emerging. This chance element is crucial, but it’s not entirely random—it’s bounded by the collective unconscious, aiming to reveal hidden connections and ideas.
This led me to a recent research question: Can new surrealist games help develop critical consciousness around artificial intelligence? After studying generative AI algorithms, I designed surrealist game called Pixelated Dreams for my MxD students at the University of Florida. The game helps them understand the stable diffusion algorithm behind DALL-E.
These students played the game to grasp this complex algorithm, which even many computer scientists struggle to fully understand. I’m confident my students wouldn’t be able to decipher technical papers by Rombach and others explaining generative AI. Yet, I felt compelled to act because my students were either interested in or already using generative AI in their work. This was especially relevant as they were teaching assistants, and some of our undergraduates had begun experimenting with these tools.
We had to discuss what this means for graphic design education, and that’s exactly what we did. Here’s how I approached this game. Instead of creating something from scratch, I typically design surrealist games and other kinds of games by appropriating existing toys or games. I mix and match different parts to create something new. In this case, I repurposed Pixobitz, a water-fuse beads toy. There are several fuse bead toys out there; some use an iron to fuse the beads. Typically, kids arrange beads to create images, and then use an iron to fuse them, resulting in a physical object that stands on its own.

Pixobitz requires only water and is faster than the others. After spraying water on the beads, you let them dry, and the object becomes sturdy after a few minutes. You can even add stickers. I didn’t use stickers because I wanted to focus on the pixels, using them as an analogy for the pixels generated by the stable diffusion algorithm.
This is an ongoing research project, part of a larger effort. I’ve been conducting embodied algorithm simulations to make complex algorithms more accessible. I aim to help people—especially those without a computer science background—understand these algorithms. Most people cannot grasp algorithms by reading academic papers or source code. I want more people to publicly scrutinize algorithms and understand the human-to-human interactions they mediate.

Many believe that what happens inside a computer stays within the computer, with no social or environmental consequences. However, I’m increasingly aware of the significant environmental impact of generative AI due to its high energy consumption. From my past experience, I’ve explored embodied algorithms to demonstrate their impact on political deliberation. For example, I worked on four projects—Pairwise, Delibera, Git, and Facebook EdgeRank—with the Brazilian Government. They wanted to evaluate social participation tools. We posed questions like: What if the Brazilian Constitution were hosted on GitHub, allowing citizens to propose amendments through pull requests? This concept would only make sense if the public understood how Git works and how it differs from the current legislative process.
I’ve also used embodied simulations for other algorithms. For instance, I developed a BOIDS simulation for my design students, helping them explore emergent behavior and complexity in interaction design. Another project involved simulating the Hungarian algorithm to distribute tasks among workers. In this scenario, participants played roles in a dystopian future where precarious “Lumpa” designers perform design tasks, such as creating a logo, for as little as five dollars. Through these examples, we aimed to reveal the human-to-human interactions embedded in computer algorithms. When people understand these interactions, they can engage more critically with computers.
This is evident in the behavior of YouTubers. Once they figure out how the YouTube algorithm works, they adapt their content strategies, sometimes even offering critical commentary on the algorithm within their videos. This dynamic can apply to any platform when users become more aware. Similarly, I wanted my design students to develop critical awareness of how generative AI algorithms work, particularly the stable diffusion algorithm.
Before we start actually generating images in the Surrealist game Pixelated Dreams, we begin by closing our eyes and recalling a recent dream. If they don’t remember any dream, they can rely on the last dream someone shared with them. Here’s how they started the game: by “training the machine” with images that convey those recent dreams. It’s a challenging task in terms of visual representation because there are only a few pixels available to depict something inherently complex. Even if I asked them to represent the dream using just pen and paper, they would struggle. Using pixels is even harder. Once they completed their image, they wrote a one-word label. This difficulty is an essential part of the challenge, as with any game, right?
Each player created their own image, spraying water to fuse the beads together. They had to wait a few minutes—not too long. If the image became too fixed, it couldn’t be taken apart, which is a crucial aspect of the denoising process. Once the images were generated, a few selected players, called prompt engineers, combined the available labels and could even add new, connecting words. These new words were written on pink sticky notes, while the original labels from the images were on blue sticky notes. The prompt engineers then compiled these labels and words to generate a new dream—a more complex one. They didn’t need to use all the labels.
After devising the dream, the requested images were placed inside a jar. Some of the images were slightly damaged—missing parts or broken—but that wasn’t a problem. The next step involved adding random pixels, a process called noising. Shaking the jar completed the process, which is also referred to as forward diffusion. The players initially reacted with concern, thinking, “Oh my gosh, all the images are going to be destroyed, completely destroyed!” But no, what comes out of the jar is only partially random and partially associated with semantics, roughly speaking.
Originally, each image represented a concept tied to a label. The relationships between these concepts are reflected in the “stickiness” of the beads. Pixels remain somewhat clustered because of their semantic association. If you retrieve one pixel, which is typically associated with another, you should be able to retrieve the whole cluster. This is the basic premise behind diffusion models. The pixels in the images carry a meaning that relates to their context when used together. For example, if there’s a request to generate an image of a heart, the retrieved pixels will likely have warm colors, as hearts are often depicted that way. Moreover, if you ask for a heart, it might speculate that hearts typically appear in the context of a human body and generate the surrounding anatomy or another relevant context, depending on the associated words.
That’s why the role of the prompt engineer is so important. They are tapping into semantic associations, not authoring specific pixels, but rather working with the networks that will generate pixels in the next step, which is denoising. The players were divided into different groups. At this point, they were no longer playing as humans but as computers, specifically GPUs (Graphics Processing Units). In this case, there were two GPUs, each composed of four players. Their task was to respond to the prompt and generate an image that conveyed the new dream.
Here you can see an example of one group working through the key steps in the generation process. Many hands are reaching out to the pixels, removing noise. Initially, it’s just a mess. The entire mess isn’t shown in this picture because some pixels are scattered on the table, but you saw it in the previous image, right? That’s the mess they’re denoising—removing the noise and separating the pieces. As they do this, they keep connected pieces apart. However, the meanings and purposes of these pieces may change as they assemble the new image.
Once the image is assembled, they spray water on it to fix it, making it ready for presentation to the prompt engineer or anyone else interested. As you can see, this process involves a kind of collective creativity, similar to what generative AI does. The artists are working behind the scenes, but remember, they’re like zombies, slaves, or anonymous contributors. That’s what these students are mimicking. I kept telling them, “Don’t speak! You’re just a computer now. No talking.” They laughed, but it underscored a critical point: this is how generative AI treats artists. Although there are no real artists in the process, this is essentially what happens: artists are silenced and turn invisible.
Multiple artists are actually contributing to generate that image because, without the training, there would be nothing. AI wouldn’t be able to do it because AI is not intelligent at all. The intelligence that AI embodies is the intelligence of the artists who trained it, all right? It’s simply making that collective intelligence or collective consciousness available for the prompt engineer. In fact, the prompt engineer could also tap directly into that collective consciousness without going through the AI. That’s why we wanted to compare what a human prompt engineer, without using AI, would generate using the same prompt and contrast it with the GPUs. This added a competitive aspect to the game.
Here, you can see the image generated by the human prompt engineers. It doesn’t seem to respond well to the prompt. It’s chaotic—”Wow, there are so many things!” You can’t even distinguish what the image is about. This is because they worked without constraints. They didn’t draw from the images pulled from the jar, which were already semantically linked, so they could freely create something entirely new. They didn’t have to engage with the semantic associations objectively embedded in the system, relying instead on their on-demand creativity to conjure whatever came to mind.
After the GPUs (GPU1 and GPU2) generated their images, the prompt prompt engineer then voted on which of the images best conveyed the prompt: “The alien feels tiredness and fatigue after rollercoastering in Tehran, then takes a cruise to Ghana”. This bizarre prompt was devised by the prompt engineers. Surprisingly, their own image was not highly favored, even by themselves. They preferred the outputs of GPU1 and GPU2.
We didn’t stop the experiment there, as it highlighted a significant limitation of current generative AI systems: they lack explainable AI. This emerging paradigm demands that generative AI provide resources to interrogate its outputs. How did it generate this image? Why did it make that decision? If AI cannot offer a satisfactory explanation, users may feel unsafe, relying on a technology they don’t understand. On the other hand, a well-explained output could provide more trustworthy interactions, fostering a fairer, more just, and more scrutinizable AI.
Though explainable AI isn’t widely available yet, we simulated this process in our game. After the first round of voting, we asked the players to explain their artwork. Once each group explained their images, we conducted another round of voting to assess whether the explanations impacted the aesthetic perceptions of the images. And they did. While not a massive shift, the human prompt engineer gained an extra vote, and GPU2 lost one vote. Despite this, GPU2 still won the game, likely because its minimalistic and efficient design left a stronger impression on the viewers.
After playing Pixelated Dreams, we analyzed MidJourney, one of the most popular generative AI tools among graphic designers. We used the same surreal prompt: “The alien feels tiredness and fatigue after rollercoastering in Tehran, then takes a cruise to Ghana.” One of the images MidJourney generated, displayed in the top right corner, was bizarre. Some Iranian and Ghanaian students in the cohort remarked, “That’s not Tehran”; “that’s not Ghana.” The image was an interpolation of these two vastly different places, which is why it resembled neither. For example, the roller coaster appeared underdeveloped, reflecting biased data in MidJourney’s dataset. When the students asked, “Can you request an image of Ghana?” the result showed only underdeveloped rural scenes, ignoring modern urban centers like Accra. This reinforced the prejudiced view held by many in the Global North, as if Africa were uniformly underdeveloped or primitive in the eyes of former colonizers.

This experience made the students aware of generative AI’s biases, prompting critical scrutiny. They recognized that tools like MidJourney can hallucinate, fabricate, and even “lie.” As one student put it: “AI was lying to us about what Ghana or Tehran is.” This led to a philosophical question: Can AI lie if it doesn’t know what truth is? Training AI doesn’t teach it truth. So what is truth? Is it just a real image of a real world? What if our world is already hyper-real? How can we distinguish truth from falsehood?
This was a difficult conversation, with no clear resolution. However, I was pleased that the students began to understand the biases inherent in generative AI, which can automate creative tasks and potentially make their design work obsolete or precarious. Yet, if we use AI to foster new forms of collective intelligence, we can subvert its inherent biases. As the Surrealists taught us, we can use rationality against itself.
If we want truly Surrealist machines in the future—because DALL·E is not Surrealist; it’s hyper-realist—we must recognize both visible and invisible artists. By “visible,” I mean giving credit where it’s due, allowing people to show their contributions. Explainable AI could help, enabling users to ask, “Which artist inspired this image? Whose work was referenced?” This could ensure fair attribution, perhaps under Creative Commons. At the same time, we should preserve the invisible, collective consciousness that generative AI taps into—the ghosts, the aliens, the Martians, if you will. This collective aspect must remain integral to the process. Current generative AI is halfway there, offering glimpses of collective consciousness. However, without control over its parameters, we can’t ensure a less biased, more inclusive output.
Ultimately, we need a balance between visibility and invisibility, with the threshold of visibility publicly scrutinized. Through participatory design, involving designers, artists, and the public, we can train, retrain, and untrain these systems to better serve society. These are the references for this talk. You can find the full list on my website. Thank you for watching.
References
Baudrillard, J. (1994). Simulacra and simulation. U of Michigan P.
Echevarria, Ivan. Creating and morphing Lego faces with neural networks. https://www.echevarria.io/blog/lego-face-vae/index.html
Fonseca Braga, M., M. C. van Amstel, F., and Perez, D. (2024) Social Design at the Brink: Hopes and Fears., in Gray, C., Hekkert, P ., Forlano, L., Ciuccarelli, P . (eds.), DRS2024: Boston, 23–28 June, Boston, USA. https://doi.org/10.21606/drs.2024.1538
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2), 3.
Brotchie, A., & Gooding, M. (Eds.). (1995). A book of surrealist games. Boston, MA: Shambhala Redstone Editions.
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10684-10695).